Covers chapter 1 from Géron’s book
Machine learning: Definition and applications
Machine learning is the art of programming computers so that they can learn from data. A more precise definition is: “A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.”
Some jargon: Training set: the examples a system uses to learn
Training instance or sample: an individual training example
Model: The part of a machine learning system that learns and makes predictions (ex. neural networks and random forests)
Data mining: digging into large amounts of data to discover hidden patterns
Why should I use machine learning?
- If my code has a long list of rules (say regex) or requires excessive fine-tuning it’s better (in both simplicity and performance parameters) to train a model for that problem.
- Finding underlying patterns within my data and insights for complex problem. I am doing a version of this in magpie.
- A machine learning system can be automated, as in it can be retrained on new data.
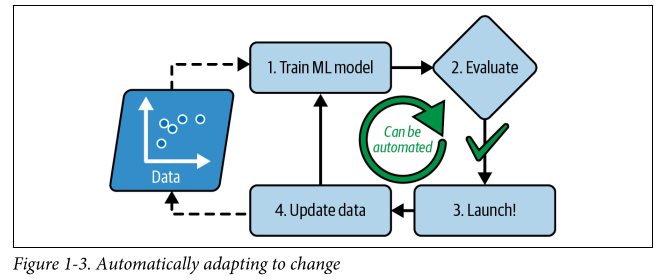
- Some complex problems (as seen in applications) for which no traditional approach has a satisfactory solution.
Some examples of applications include:
- Detecting tumors in brain scans (image segmentation using CNNs or transformers)
- Classification of news articles (natural language processing, text classification using RNNs and CNNs or transformers)
- Forecasting based on performance metrics (regression, value prediction)
- Voice commands (speech recognition, again using RNNs, CNNs or transformers)
- Segmenting data (clustering)
- Representing a high dimension dataset into an insightful diagram (dimensionality reduction and data visualisation)
- Building an intelligent bot (reinforcement learning)
Types of machine learning systems
We use the following criteria to classify ML systems:
- How they’re sueprvised during training (supervised, unsupervised, semi-supervised, self-supervised, etc.)
- Whether they can learn incrementally on the fly for latest data (online and batch)
- Whether they are comparing new data points to old known data points or are detecting patterns within the data using a predictive model like irl scientists (instance-based and model-based)
Training supervision
Classification on basis of amount and type of supervision received during training.
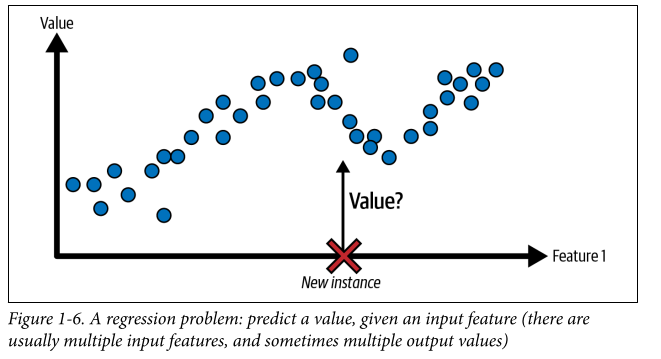
Supervised learning: Here, the training fed to the models includes desired solutions called labels. Things that can be done in supervised learning include classification of new data (training data would also have class assigned to it), target value prediction (ex. price of a car given a set of features like brand, mileage, color)- this is called regression. Regression models can also be used for classification and vice versa.
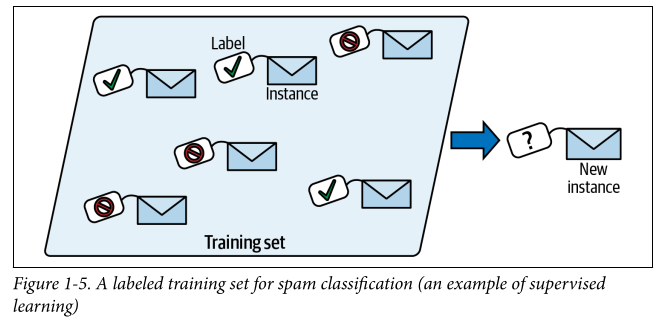
NOTE
target and label are generally synonyms in supervised learning but target is more common for regression tasks and label is more common for classification tasks. Features are also called predictors/attributes. Ex. “this video’s viewcount feature is 100,000” or for entire sample, “the tags feature is not correlated with the view count”.
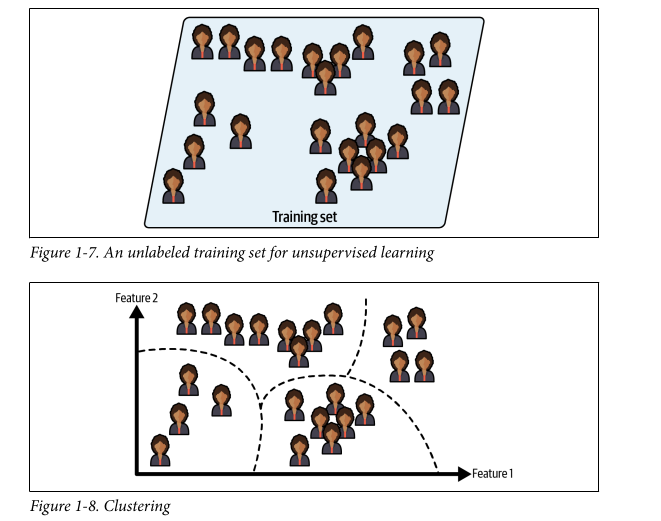
Unsupervised learning: Training data is unlabeled in this. Example - running a clustering algorithm on a dataset to try to detect similar groups of data. Heirarchal clustering may also help to find sub-groups within those groups. Another example of unsupervised learning is data visualisation - feed them lots of complex unlabeled data and they’ll spit out a 2d/3d representation that can be plotted. This is good for identifying patterns within your data too. Another task is dimensionality reduction where you try to simplify data without losing too much information by trying to merge several correlated features into one (ex. car’s mileage is correlated to its age). This is called feature extraction. Yet another task would be anomaly detection: the system is shown normal instances during training and when it sees a new not-normal instance it flags it as an anomaly. Similarly there’s novelty detection: requires a clean state training data devoid of the thing you would like to detect. Then when something new is seen it’s flagged as a novelty. The last one is association rule learning - the goal is to dig into large amounts of data and find interesting relationships between the attributes.
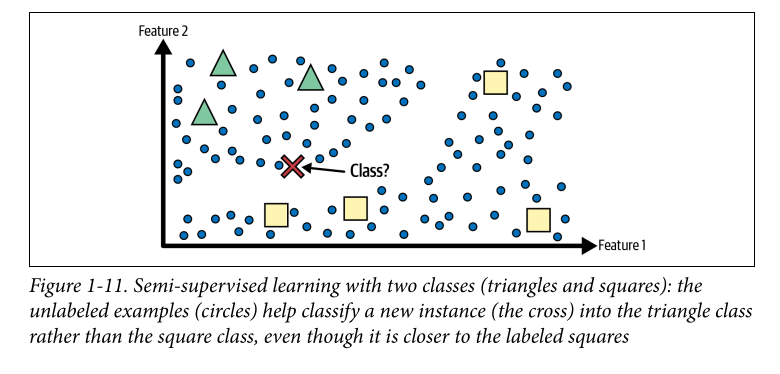
 Semi-supervised learning: Some algorithms can deal with partially labeled data (this is very common, it seems), this is called semi-supervised learning. Ex. using a clustering algorithm to group similar instances together and then labeling every unlabeled instance with the most common label in that cluster. This is what Google Photos uses to identify people in images (first clustering them - unsupervised, and then and then asking you for label)
Semi-supervised learning: Some algorithms can deal with partially labeled data (this is very common, it seems), this is called semi-supervised learning. Ex. using a clustering algorithm to group similar instances together and then labeling every unlabeled instance with the most common label in that cluster. This is what Google Photos uses to identify people in images (first clustering them - unsupervised, and then and then asking you for label)
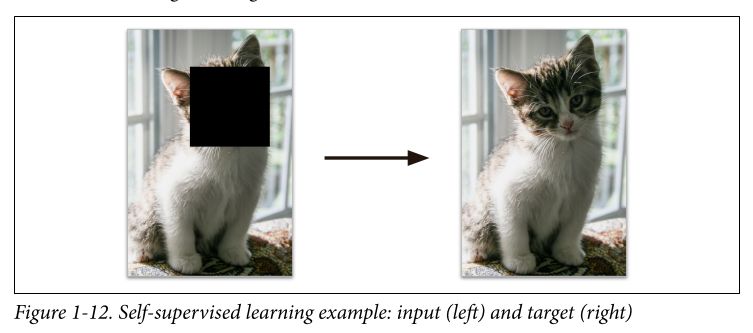
 Self-supervised learning: Involves generation of a fully labeled dataset from a fully unlabeled one. After the whole dataset has been labeled any supervised learning algorithm can be used. This is usually not the final step but an intermediate one, the model may be fine-tuned later to perform some other task. Ex. you could mask certain parts of an image in a large dataset of unlabeled images and then train a model to complete the image. Here the complete image is the label. This functions well as an intermediate step, the resulting model can be used for repair damaged images or erase objects but if you want a model that can recognise species of animals it’s not quite there yet. For that you could wait until the model is performing well at the image repairing task (on which it was trained using self supervised) and then tweak the architecture to make it predict species instead of repairing images (most neural net architectures allow for this). The final step would be to finetune the model on a labeled dataset. The model already knows what the different species are, so in this step we only want it to “map” it to the correct species.
Self-supervised learning: Involves generation of a fully labeled dataset from a fully unlabeled one. After the whole dataset has been labeled any supervised learning algorithm can be used. This is usually not the final step but an intermediate one, the model may be fine-tuned later to perform some other task. Ex. you could mask certain parts of an image in a large dataset of unlabeled images and then train a model to complete the image. Here the complete image is the label. This functions well as an intermediate step, the resulting model can be used for repair damaged images or erase objects but if you want a model that can recognise species of animals it’s not quite there yet. For that you could wait until the model is performing well at the image repairing task (on which it was trained using self supervised) and then tweak the architecture to make it predict species instead of repairing images (most neural net architectures allow for this). The final step would be to finetune the model on a labeled dataset. The model already knows what the different species are, so in this step we only want it to “map” it to the correct species.
NOTE
this is also called transfer learning, and is a very important technique in ML
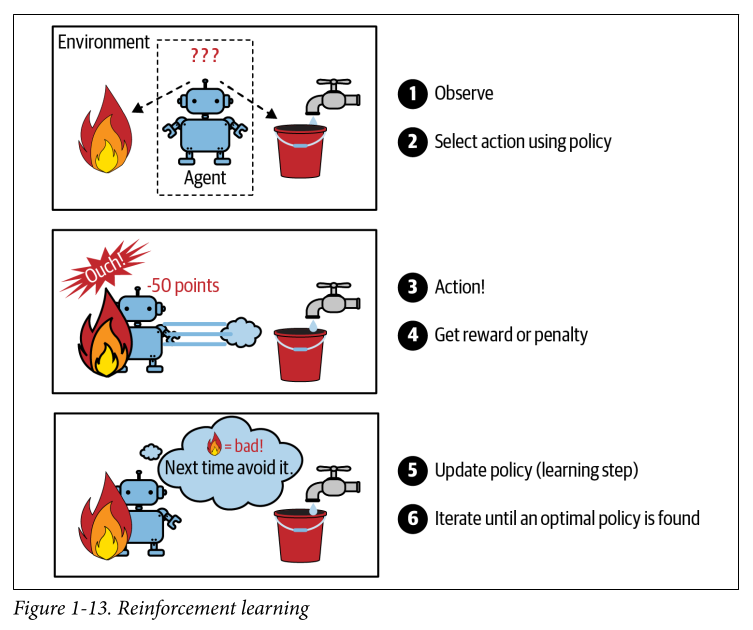
Reinforcement learning: We call the system that is learning an agent here. We either give it rewards or penalties for its actions and it must select the best strategy aka policy to get the most rewards. A policy directs the agent’s action here.
Online and batch learning
Can the model learn incrementally from a stream of incoming data?
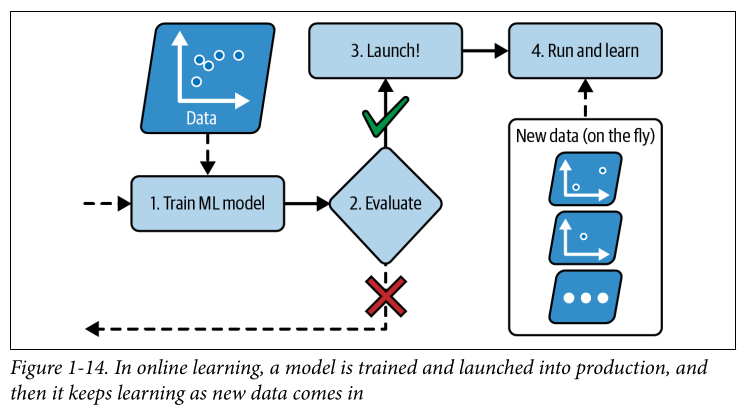
Batch learning: the system is incapable of learning incrementally and should be trained offline using all available data at the time. This takes a lot of time and compute. I think large language models are trained using this - as the model runs in production without learning anymore. Thus this is offline learning.
In this the system suffers from something called model rot or data drift in which the model’s performance decays over time. If you want it to get updated with the latest data, you need to train it again on the entire dataset (old+new) and that takes up a lot of computing resources. In autonomous systems or in situations where resources are limited, this is undesirable and we want a better solution.
Online learning: Think of it more as incremental learning, the model fed data instances in small groups called mini batches. The learning step here is fast and the model can learn new data really quickly. This is essential in places where the model should be aware of new data (ex. stock market predictions) or if you have limited computing resources. Online learning algorithms can also be used to perform out of core learning where the model is trained on a huge dataset offline using incremental steps.
One more parameter to be aware of here is the learning rate. Higher learning rate = more adaptability for new data = forgetfulness of old data. Lower learning rate = more inertia.
Some risks here are performance drops because of new “bad” data. You can turn learning off for this or use an anomaly detection algorithm to detect bad data.
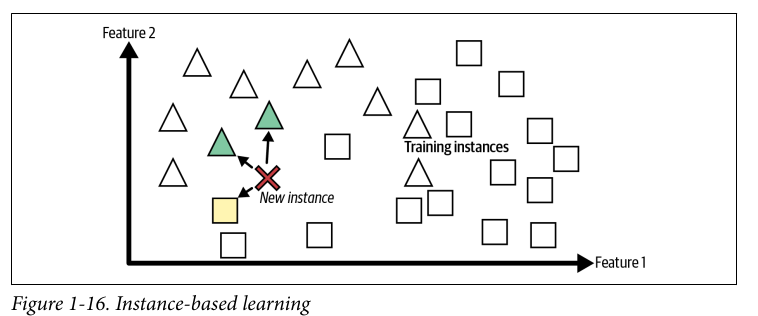
Instance and Model based learning
Instance based learning: you make the system compare a new instance to old instances and then infer what class the new instance belongs to. You need a measure of similarity for this. This is instance based learning, the system learns the examples by heart and generalises to new use cases by comparing them using a similarity measure.
Model based learning: you make a model out of the examples and then use that model to make predictions. Example of a model: a linear model of course, there would be some model parameters (here rep. by theta). To know which values make your model perform best you either create a fitness/utility function to tell you how good your model is or a cost function to tell you how bad it is. For linear regression a cost function is used to measure distance between the model’s (equation) predictions and the examples. Then this distance (cost function) is to be minimized. This is the work for the algorithm, to find the optimal values for my model. Application of the model to new cases is called inference.
utility function - higher is better cost function - lower is better
NOTE
The word “model” can refer to a type of model (ex. linear regression), a fully specified architecture (linear regression with 1 i/p o/p) or the final trained model ready for predictions (equation). Model selection is choosing a model type and specifying its architecture. Training a model means running an algorithm to find the model parameters that will make it best fit the training data and make predictions on new data.
Some challenges in machine learning
Because you have to select a model and train it on data these challenges are either of the type “bad model” or “bad data”.
“Bad” data
- insufficient quantity, data selection might be more imp. than algorithms for a huge corpus. See the paper “The Unreasonable Effectiveness of Data”
- nonrepresentative data which can make your model make inaccurate predictions on outliers. If the sample is too small you run into sampling noise (nonrepresentative data as a result of noise), if it’s too large you run into sampling bias. How do you even get this right?
- poor data, most data scientists spend most of their time doing data cleaning. If some instances are outliers, discard them or deal with them manually. If some instances are missing some features, you might want to ignore those attributes, ignore those instances, or fill in missing values, or train two models - one with feature in and one without it. This is exactly the problem I am running into with magpie.
- irrelevant features - feature selection (selecting most useful features to train on), feature extraction (creating a new feature using existing ones, using dimensionality reduction for ex.), creating new features by gathering new data.
“Bad” algorithms
- overfitting: the model performs well on training data, but does not generalize well. This happens when a model is too complex relative to amount and noisiness of training data. Some solutions are:
- simplify the model by selecting one with fewer params
- gather more training data
- reduce the noise in the training data (ex. fixing data errors or outliers)
Constraining a model to make it simpler and to reduce the risk of overfitting is called regularization.
The amount of regularization to be applied during learning is called a hyperparameter. It’s a parameter of the learning algorithm, not of the model. It must be set prior to training. Tuning hyperparameters is a very important part in building a ML system.
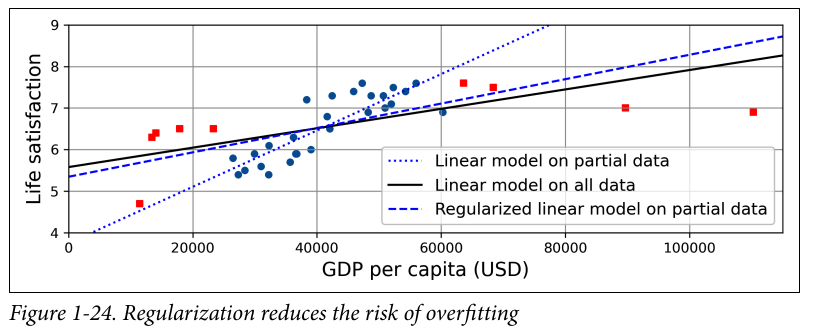 why is it true that simpler models generalise well? maybe because more complex models are more susceptible to overfitting? why is that so?
why is it true that simpler models generalise well? maybe because more complex models are more susceptible to overfitting? why is that so?
- underfitting: model is too simple to learn the underlying structure of the data.
- select a more powerful model with more params
- find better features (feature engineering)
- reduce the constraints (ex. reducing regularization hyperparameter)
Testing and validating a model
split your data into two sets: training set and test set. Error rate on new cases is known as generalization error.
ex. overfitting - training error is low but generalization error is high (your model is tightly coupled to training data)
Generally an 80-20 split is applied for training and testing datasets.
Hyperparameter tuning and model selection: say you are hesitating between two different models, and want to choose between them. One way would be to train both and see how well they generalize in the test set. If one performs badly, say you want to tune the regularisation hyperparameter by training 100 models using 100 different values of this hyperparam and find the model with the lowest generalisation error. But this approach is bad because it couples the hyperparam to the test set, so you were producing the best model for that particular set.
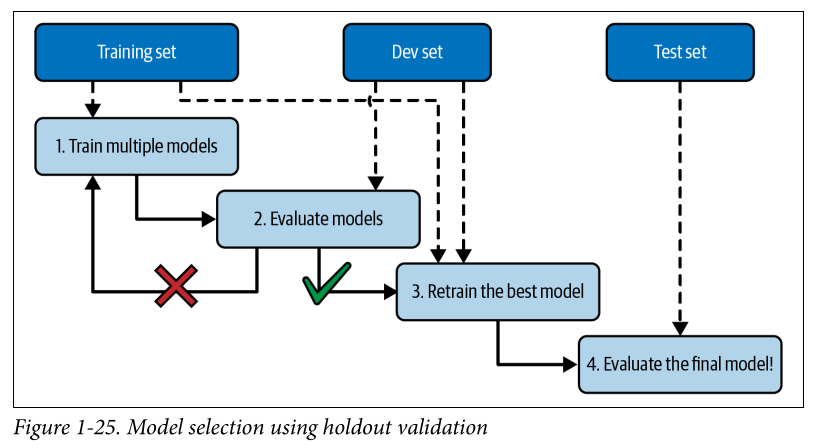
One way to solve this is by using holdout validation - hold out a part of the training set (called the validation set or dev set) to evaluate candidate models.
- You train the candidate models on the reduced training set (training set - validation/dev set) and select the model that performs best on the validation set.
- select whatever performs best and retrain it on the full training set (including validation set)
- evaluate the final model on the test set to get an estimate of generalization error
cross validation: selecting many small validation sets.
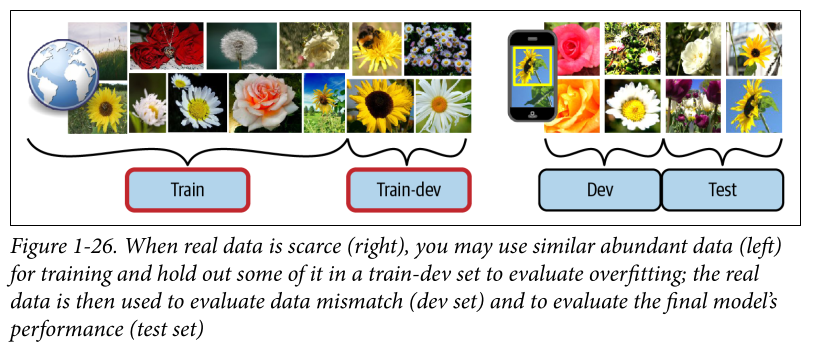
Data mismatch: sometimes you won’t have good data. A possible solution here, as proposed by Andrew Ng is to create a train-dev set. The process would work as follows; in this example I am trying to train a model to recognise the species of flowers taken from my mobile app.
- train the model on pictures available on the web (as I don’t enough data/images from the app itself). Hold out some of the images from the web in a separate train-dev set.
- see how the model performs on the train dev set. If it performs poorly, it has overfit the training set so regularization/simplification/data cleanup is required.
- if it performs well test it on the dev set (actual images from your app)- if it performs poorly here it’s because of data mismatch - you should try to imitate the images taken from an app using the web images by editing them or whatever
- if it performs well on dev set proceed to test it on the test set
NOTE
If you make absolutely no assumptions about the data then there is no reason to prefer one model over another. There is no model that is a priori guaranteed to work better. This is the “no free lunch” theorem. This, to me, points to a deeper epistmological problem here - when you select a model, you are making assumptions about the data. Of course, in theory you could test 100 different models but in practice it’s reasonable to make assumptions, ex. simpler models for simple problems, more complex ones for harder problems.